What Is Ai Acceleration In Modern Hardware
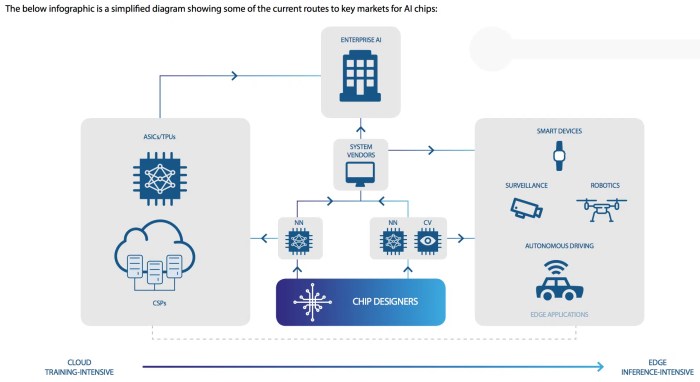
What is AI acceleration in modern hardware? This exploration delves into the core concepts, highlighting the critical role of specialized hardware in powering AI advancements. From defining AI acceleration and its key components to contrasting general-purpose processors with dedicated AI accelerators, we’ll examine the diverse landscape of modern hardware solutions. Understanding the strengths and weaknesses of different accelerator types, such as GPUs, FPGAs, and TPUs, is key to comprehending the specific needs of various AI applications.
The discussion extends to hardware architectures tailored for AI tasks, examining design choices that optimize performance. We’ll analyze the impact of memory hierarchies and interconnect technologies on acceleration speed, providing concrete examples. Furthermore, the critical role of software optimization in leveraging these accelerators will be covered. Specific examples of how these techniques translate to improved performance in applications like image recognition and natural language processing will be demonstrated.
Defining AI Acceleration
AI acceleration in modern hardware refers to the significant performance boost achieved by specialized hardware designed specifically to handle the computationally intensive tasks required for artificial intelligence (AI) workloads. This specialized hardware, often distinct from general-purpose processors, significantly reduces the time needed for training machine learning models and running AI inference tasks. This speed improvement is crucial for deploying AI applications in real-world scenarios, from image recognition to natural language processing.AI acceleration hinges on the concept of tailoring hardware architecture to the specific numerical computations prevalent in AI algorithms.
This contrasts sharply with general-purpose processors that are designed for a wider range of tasks, leading to less efficient performance for AI tasks. Modern AI workloads often involve massive matrix multiplications, complex neural network operations, and other computationally intensive operations that benefit greatly from dedicated hardware.
Key Components of an AI Acceleration System
The core of an AI acceleration system is dedicated hardware, designed specifically for AI tasks. This often includes specialized processing units optimized for parallel computations and data movement. Memory hierarchies, crucial for rapid data access, are also meticulously designed for AI workloads. Interconnects between processing units and memory are optimized for low latency and high bandwidth to enable fast data transfer.
Software frameworks and libraries are developed to effectively utilize the unique capabilities of these specialized hardware components.
Fundamental Differences Between General-Purpose Processors and AI Accelerators
General-purpose processors, such as CPUs, excel at diverse tasks but can struggle with the highly parallel, numerical-intensive computations central to AI. AI accelerators, on the other hand, are specifically designed for these types of computations. This specialization translates into significantly faster execution of AI algorithms. The architectural differences are key: CPUs generally rely on sequential execution, whereas AI accelerators employ parallel processing, which is more suited to AI’s inherent parallelism.
This specialization allows AI accelerators to outperform CPUs by orders of magnitude in specific AI tasks.
Comparison of AI Accelerator Types
Different types of AI accelerators cater to various AI needs and have unique strengths and weaknesses. Understanding these differences is crucial for selecting the appropriate hardware for a specific application.
| Accelerator Type | Strengths | Weaknesses |
|---|---|---|
| GPUs (Graphics Processing Units) | Excellent parallel processing capabilities, massive parallelism, high throughput for matrix operations, readily available and cost-effective for many tasks. | Generally less specialized for AI tasks compared to TPUs, potentially less efficient for specific AI algorithms, can be less energy-efficient for some tasks. |
| FPGAs (Field-Programmable Gate Arrays) | Highly customizable, allowing tailoring to specific AI algorithms, potentially high efficiency for customized AI tasks. | Requires significant expertise for design and programming, generally less mature software ecosystem compared to GPUs, higher cost compared to GPUs for similar performance. |
| TPUs (Tensor Processing Units) | Designed specifically for tensor operations (common in deep learning), highly optimized for deep learning workloads, often exhibit superior energy efficiency and performance for AI tasks, particularly deep learning. | Generally more expensive than GPUs, limited availability, specialized software ecosystem for programming and utilization. |
Hardware Architectures for AI Acceleration
Modern AI tasks demand significant computational power, driving the development of specialized hardware architectures. These architectures are meticulously designed to optimize performance for various AI algorithms, fundamentally altering how AI applications are deployed and scaled. The evolution of these architectures reflects the ongoing quest for greater efficiency and speed in processing vast datasets.Different hardware designs excel at specific AI operations.
Understanding these architectural choices is crucial to effectively leverage these systems for optimal performance and cost-effectiveness. For instance, a system designed for image recognition might have different characteristics than one optimized for natural language processing. The specific choices in architecture directly impact the performance of the system, thus necessitating a careful understanding of these choices.
Different Hardware Architectures
Various hardware architectures have emerged to address the diverse needs of AI acceleration. These architectures cater to different types of AI algorithms and operations, each with unique strengths and weaknesses. Understanding these differences allows for selecting the appropriate architecture for a specific AI task.
- Graphics Processing Units (GPUs): GPUs, initially designed for graphics rendering, have proven highly effective for parallel computations inherent in many AI tasks. Their massive parallel processing capabilities, coupled with high memory bandwidth, make them a cornerstone in many AI systems. For instance, deep learning models are frequently trained and run on GPUs.
- Tensor Processing Units (TPUs): Designed specifically for tensor operations, TPUs offer optimized hardware for deep learning workloads. Their architecture is tailored for matrix multiplication, a core operation in many AI algorithms, leading to significant performance improvements compared to general-purpose processors. Google’s extensive use of TPUs in its AI infrastructure exemplifies this specialization.
- Field-Programmable Gate Arrays (FPGAs): FPGAs provide high levels of customization, allowing hardware designers to tailor the architecture to specific AI algorithms. This flexibility makes FPGAs suitable for specialized tasks where optimal performance is paramount. Their programmability also enables adaptation to evolving AI models and algorithms.
- Neural Processing Units (NPUs): NPUs are emerging as a dedicated hardware solution for AI tasks. They often integrate specific hardware components designed to accelerate neural network operations, potentially offering performance gains over GPUs and TPUs for specific AI algorithms. These systems aim to optimize operations in AI models.
Design Choices for AI Acceleration
The design choices in a hardware architecture profoundly impact its suitability for AI tasks. Factors like memory bandwidth, interconnect speed, and parallel processing capabilities directly affect performance.
- Memory Hierarchy: The memory hierarchy, ranging from cache to main memory, plays a critical role. A system with a fast, high-capacity memory hierarchy can significantly reduce latency in accessing data, a crucial element for achieving high performance in AI tasks. Modern AI systems prioritize large caches and high bandwidth main memory to handle the massive datasets.
- Interconnect Technologies: The speed and efficiency of communication between different components in the hardware architecture are critical. High-bandwidth interconnects, like those using specialized fabrics or optimized network interfaces, enable rapid data transfer between processing units and memory, minimizing latency and maximizing performance. Efficient communication is essential for complex AI operations.
- Parallel Processing Capabilities: Many AI algorithms inherently benefit from parallel processing. Hardware architectures designed with a large number of processing cores and optimized communication channels between them can dramatically accelerate AI computations. The ability to perform multiple operations simultaneously is a crucial element of a well-designed AI hardware system.
Architectural Elements Enhancing AI Performance
Specific architectural elements are crucial for maximizing the performance of AI algorithms. A well-designed system will have elements optimized for particular operations in AI.
- Specialized Instructions: Hardware instructions tailored for AI operations, such as matrix multiplications or tensor operations, can significantly accelerate processing. These specialized instructions directly target the mathematical operations common in AI models.
- Data Formats: Optimized data formats that reduce memory usage or enhance computation speed can enhance performance. For example, using specialized data structures for tensors can reduce memory access time and improve overall performance in deep learning applications.
Memory Hierarchy in AI Acceleration
The memory hierarchy significantly impacts AI acceleration. The ability to quickly access data stored in different levels of the memory hierarchy is essential. This hierarchy often includes caches, main memory, and potentially even persistent storage.
- Cache Optimization: Efficient cache design minimizes latency in data retrieval, directly impacting performance. AI workloads often involve repeated access to the same data, so optimized caches are critical for speed.
- Memory Bandwidth: High memory bandwidth is essential for handling large datasets, which are common in AI applications. This bandwidth allows for rapid data transfer between different components of the system, reducing latency and improving overall performance.
Impact of Interconnect Technologies
Interconnect technologies play a crucial role in AI acceleration. The speed and efficiency of data transfer between processing units and memory impact performance.
- Interconnect Bandwidth: High-bandwidth interconnects are essential for handling the large amounts of data exchanged in AI computations. A system with a high-bandwidth interconnect can support the data transfer requirements of modern AI workloads.
- Interconnect Latency: Low latency is critical to minimize delays in data transfer between different parts of the system. Low latency interconnects are vital for optimal performance.
Table of Hardware Architectures
| Architecture | Description | Key Features |
|---|---|---|
| GPU | Graphics Processing Unit | Parallel processing, high memory bandwidth, widely available |
| TPU | Tensor Processing Unit | Optimized for tensor operations, high performance in deep learning |
| FPGA | Field-Programmable Gate Array | Highly customizable, suitable for specialized AI tasks |
| NPU | Neural Processing Unit | Dedicated hardware for neural network operations, potential for high performance |
Software Considerations for AI Acceleration: What Is AI Acceleration In Modern Hardware
AI acceleration hinges not just on specialized hardware, but also on corresponding software adaptations. Optimizing software for these accelerators unlocks their full potential, leading to significant performance gains and enabling new applications. This involves a multifaceted approach, from modifying programming models to implementing efficient optimization techniques.The key to harnessing the power of AI accelerators lies in crafting software that can effectively communicate with and utilize their unique architectures.
This requires a shift from traditional programming paradigms to those that exploit the parallel processing capabilities of these advanced hardware components.
Programming Models and Libraries for AI Acceleration
Developing AI software tailored for accelerators necessitates the adoption of suitable programming models and libraries. These tools provide the abstraction layer needed to express complex AI algorithms in a way that efficiently leverages the underlying hardware. Popular choices include Tensorflow, PyTorch, and CUDA, each with strengths in different aspects of AI acceleration. These libraries often provide optimized kernels for common operations, further enhancing performance.
Optimization Techniques for AI Workloads
Optimizing AI workloads on accelerated hardware is crucial for achieving maximum performance. This involves several key techniques, such as algorithmic optimization, data layout adjustments, and memory management strategies. Algorithmic optimization may involve restructuring the algorithm to better align with the hardware’s capabilities. Data layout adjustments are vital to ensure that data is transferred and accessed efficiently. Memory management techniques, such as caching and data prefetching, are also important to minimize latency.
Examples of Software Frameworks Tailored for AI Acceleration
Various software frameworks are emerging to streamline the development and deployment of AI applications on accelerated hardware. These frameworks provide higher-level abstractions, simplifying the process of creating efficient AI applications. For instance, frameworks such as TensorFlow, PyTorch, and CUDA-X provide optimized implementations for common AI operations, often incorporating auto-tuning and performance analysis tools to ensure optimal code generation.
This often translates to significant performance improvements, sometimes achieving orders of magnitude gains compared to traditional CPU-based implementations.
Workflow Diagram: Software-Hardware Interaction
+-----------------+ +-----------------+
| Application Code | --> | AI Framework |
+-----------------+ +-----------------+
| |
| |
V V
+-----------------+ +-----------------+
| Data Preparation | --> | Data Transfer |
+-----------------+ +-----------------+
| |
| |
V V
+-----------------+ +-----------------+
| AI Accelerator | <-- | Optimized Kernel|
+-----------------+ +-----------------+
| |
| |
V V
+-----------------+ +-----------------+
| Results/Output | <-- | Results Return |
+-----------------+ +-----------------+
This diagram illustrates the interaction between software and hardware.
The application code, through an AI framework, interacts with the AI accelerator via data transfer and optimized kernels. The accelerator performs the computations and returns the results. The AI framework manages the data flow and communication between the application and the accelerator.
AI Acceleration in Specific Applications

Source: techslang.com
AI acceleration significantly impacts various applications, enabling faster processing and improved accuracy. By leveraging specialized hardware and optimized software, AI models can be deployed in real-time, driving advancements across numerous sectors. This section explores the transformative effects of AI acceleration on specific applications, highlighting the benefits and challenges.
Impact on Image Recognition
Image recognition tasks, crucial for applications like autonomous vehicles and medical diagnostics, experience substantial performance gains through acceleration. Specialized hardware architectures, such as tensor processing units (TPUs), are designed for the matrix multiplications inherent in convolutional neural networks (CNNs), the foundation of many image recognition models. This optimized approach dramatically reduces processing time, allowing real-time analysis of images.
For example, a self-driving car needs to rapidly identify pedestrians and traffic signs. AI acceleration enables this by speeding up the image processing, enabling the car to react quickly to changing scenarios. This leads to improved safety and enhanced decision-making capabilities.
| Application | Performance Improvement | Challenges |
|---|---|---|
| Image Recognition | Reduced latency in object detection and classification; enabling real-time analysis; enhanced accuracy in complex scenes. | Potential for high computational cost in training large models; ensuring the robustness and accuracy of the models in diverse lighting and weather conditions. |
Impact on Natural Language Processing
Natural language processing (NLP) applications, encompassing tasks like language translation and sentiment analysis, benefit from AI acceleration through the efficient processing of large text datasets. Hardware accelerators like GPUs and TPUs excel at handling the vector operations necessary for tasks like word embeddings and recurrent neural networks (RNNs). This accelerates the training and inference processes, leading to faster response times.
For instance, chatbots and virtual assistants require rapid understanding and response to natural language queries. AI acceleration enables these systems to provide near-instantaneous feedback, creating a more seamless user experience. Similarly, in machine translation, AI acceleration enables real-time translation, making communication across languages more fluid.
| Application | Performance Improvement | Challenges |
|---|---|---|
| Natural Language Processing | Reduced processing time for tasks like language translation and sentiment analysis; improved efficiency in handling large text datasets; enabling more complex NLP models to be deployed in real-time. | Maintaining accuracy and context in complex language nuances; ensuring the ethical implications of language processing are addressed. |
Impact on Other Applications
AI acceleration isn't confined to just image recognition and NLP. It impacts a wide array of applications. In scientific research, AI acceleration facilitates faster simulations and analysis of complex data, potentially leading to breakthroughs in fields like drug discovery and materials science. In finance, AI acceleration enables faster fraud detection and risk assessment, leading to more secure financial transactions.
These applications showcase the broad impact of AI acceleration. The ability to perform these tasks in real-time is essential to their efficacy. While significant improvements have been made, challenges remain, including the development of more robust and generalizable models.
Trends and Future Directions
The landscape of AI acceleration hardware is rapidly evolving, driven by the increasing demand for faster, more efficient, and specialized computing solutions. Current trends reflect a move towards heterogeneous architectures and a greater focus on energy efficiency. These advancements are poised to significantly impact various industries, driving innovation and reshaping existing processes.
The future of AI acceleration promises even more sophisticated hardware, pushing the boundaries of what's possible in terms of processing speed, power consumption, and specialized functionalities. Research in novel materials and architectures is continually pushing the limits of performance, paving the way for groundbreaking applications.
Current Trends in AI Acceleration Hardware
The current trends in AI acceleration hardware are characterized by a shift towards specialized hardware tailored to specific AI tasks. This specialization aims to maximize performance and minimize power consumption compared to general-purpose processors. Heterogeneous systems, integrating GPUs, CPUs, and specialized accelerators, are becoming increasingly common. This approach leverages the strengths of each component to achieve optimal performance for various AI workloads.
Examples include systems incorporating FPGAs for custom logic acceleration, or specialized tensor processing units (TPUs) for deep learning tasks.
Potential Future Developments in AI Acceleration Technologies
Future developments in AI acceleration technologies will likely focus on further refining specialized hardware architectures. This will involve exploring new materials and manufacturing processes to achieve higher performance and lower power consumption. Neuromorphic computing, inspired by the human brain, is a promising area of research, potentially leading to more efficient and adaptable AI systems. The development of specialized hardware tailored to specific AI tasks, such as natural language processing or computer vision, will continue to optimize performance for those workloads.
Emerging Research Areas and Innovative Approaches
Emerging research areas include the exploration of quantum computing for AI acceleration. While still in its early stages, quantum computing has the potential to revolutionize AI by enabling the solution of complex problems currently intractable for classical computers. Another significant area is the development of hardware optimized for specific AI models, such as transformer-based models used in natural language processing.
Researchers are investigating specialized hardware accelerators to significantly enhance the performance of these models.
Summary of Future Prospects of AI Acceleration
The future of AI acceleration looks promising, with continued advancements expected in both hardware and software. This progress will be driven by the increasing need for faster, more efficient AI systems across a wide range of applications. The potential impact on industries will be profound, leading to breakthroughs in areas like healthcare, autonomous vehicles, and financial modeling.
Possible Impact on Various Industries, What is AI acceleration in modern hardware
The impact of these trends on various industries will be substantial. In healthcare, AI acceleration could lead to faster diagnostics and personalized treatment plans. Autonomous vehicles will benefit from the increased processing power for real-time decision-making. In finance, AI acceleration will enable more complex risk assessments and fraud detection. Furthermore, AI acceleration will drive the development of more sophisticated and efficient systems for scientific research and industrial automation.
The possibilities are extensive, and the impact will be far-reaching.
Wrap-Up
Source: emerj.com
In conclusion, AI acceleration in modern hardware represents a significant advancement in computing capabilities. The discussion has explored the various facets of this technology, from hardware architecture and software considerations to the impact on real-world applications. The future trends and potential developments in this field are also Artikeld, providing a comprehensive view of AI acceleration's role in driving innovation across numerous industries.










Post Comment