Gpu Architecture Explained For Beginners
GPU architecture explained for beginners: This exploration delves into the fascinating world of Graphics Processing Units, revealing their inner workings and unique capabilities. From their historical evolution to their modern applications, we’ll uncover how GPUs differ from CPUs and how they excel at parallel processing. Prepare to gain a comprehensive understanding of these powerful computational engines.
This in-depth look will cover everything from the fundamental components of a modern GPU architecture to the intricacies of parallel processing and various programming models. We’ll also explore the different types of GPU memory, the data flow within the system, and showcase specific architecture examples, culminating in a discussion of future trends and applications.
Introduction to GPU Architecture
A Graphics Processing Unit (GPU) is a specialized electronic circuit designed to rapidly manipulate and alter memory to accelerate the creation of images in a frame buffer intended for output to a display device. Beyond graphics, GPUs excel at parallel processing, making them highly effective for a wide array of computational tasks. Their architecture differs significantly from that of a Central Processing Unit (CPU), leading to distinct strengths and weaknesses for each.Modern GPU architectures are highly complex, featuring numerous cores and intricate memory hierarchies.
These specialized components work in concert to achieve exceptional performance in tasks involving significant parallel computations. Understanding these components is crucial to appreciating the power and versatility of GPUs.
GPU Components and Functions
GPUs are not monolithic entities. They consist of numerous interconnected components, each with a specific role in the overall image processing and computational pipeline. This structured approach enables them to handle a massive volume of parallel operations.
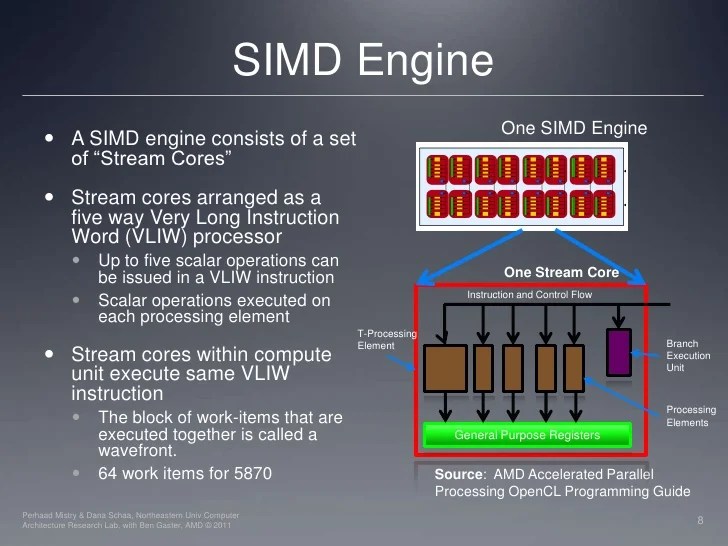
- CUDA Cores: These are the fundamental processing units of a GPU, analogous to CPU cores. They are specifically designed for parallel computations, excelling at tasks like matrix multiplication, image manipulation, and physics simulations. Each core typically executes a single instruction at a time, but many cores can execute different instructions simultaneously.
- Memory Hierarchy: GPUs employ a multi-level memory hierarchy, including registers, shared memory, and global memory. Registers are extremely fast but limited in capacity, while shared memory offers a balance between speed and capacity. Global memory, while slower, offers the largest storage space for data. This tiered approach optimizes memory access times, ensuring efficient data transfer and manipulation.
- Special Function Units (SFUs): These specialized units handle specific tasks like texture mapping, blending, and other image-processing operations. Their dedicated design ensures that these crucial tasks are performed efficiently without impacting the overall GPU performance.
- Streaming Multiprocessors (SMs): SMs are groups of CUDA cores that operate together. They are a crucial part of the GPU’s architecture, enabling efficient data transfer and synchronization between cores. The organization of SMs in a GPU significantly impacts performance, particularly in complex tasks.
- Unified Memory Architecture: This aspect of modern GPUs facilitates seamless data sharing between various memory levels. This integrated memory access enables optimal performance in parallel computations by reducing the overhead of data movement between different memory types.
CPU vs. GPU Architecture
CPUs and GPUs differ significantly in their architecture, leading to differing strengths. CPUs are generally sequential processors, handling one instruction at a time, while GPUs are designed for parallel processing, executing numerous instructions concurrently. This difference in approach profoundly impacts performance in various applications.
| Component | Function | Brief Description |
|---|---|---|
| CPU | Sequential Processing | Executes instructions one at a time, generally suitable for tasks requiring precise control flow. |
| GPU | Parallel Processing | Executes multiple instructions simultaneously, excelling in tasks involving significant parallelism, such as image processing and scientific computing. |
| CPU Memory | Sequential Access | Memory access is typically sequential, leading to potential delays when handling large datasets. |
| GPU Memory | Parallel Access | GPUs allow for concurrent memory access, reducing latency in parallel computations. |
Historical Context of GPU Development
The development of GPUs has been a fascinating journey, starting from specialized hardware for image acceleration and evolving into the versatile computational engines we see today. Early GPUs were primarily focused on graphics, but their capabilities expanded over time, allowing for wider applications. The rise of parallel computing has driven the evolution of GPU architecture, leading to more efficient and powerful devices.
“The evolution of GPUs from simple image accelerators to general-purpose computing platforms reflects a shift in how we approach complex computational problems.”
Parallel Processing
Parallel processing is a computational strategy that involves executing multiple tasks simultaneously. This approach contrasts with sequential processing, where tasks are performed one after another. Leveraging multiple processors or processing units enables faster completion of complex calculations and operations.This fundamental difference in processing methodologies significantly impacts the performance of various computational tasks. Different hardware architectures, such as CPUs and GPUs, excel at handling parallel processing in distinct ways, offering varying levels of efficiency and effectiveness.
The ability to perform calculations in parallel is crucial for many applications, from scientific simulations to video games.
GPUs and Parallel Processing
GPUs are specifically designed for parallel processing, far surpassing the capabilities of CPUs in this area. This specialization is reflected in their architecture, featuring numerous smaller processing units, in contrast to CPUs’ reliance on fewer, more complex units.
Advantages of Parallel Processing in Applications
Parallel processing significantly enhances performance in numerous applications. For example, in scientific simulations, complex models can be computed more rapidly, leading to more accurate and detailed outcomes. In video games, realistic graphics and smooth animations become possible due to the speed and efficiency of parallel processing. The rendering of images, critical in image processing and computer graphics, also benefits significantly from parallel processing.
Comparison of Parallel Processing Models
Various parallel processing models exist, each with its strengths and weaknesses. Data parallelism, a common approach, involves distributing identical tasks across different processing units. Task parallelism, another model, divides a larger task into smaller, independent sub-tasks that are then processed concurrently. Hybrid approaches combining data and task parallelism often prove most effective for complex workloads. The selection of a suitable parallel processing model depends on the nature of the task and the characteristics of the available hardware.
Illustrative Flowchart of GPU Parallel Operations
A GPU, in performing parallel operations, essentially breaks down a complex calculation into smaller, independent operations that are then executed concurrently across its many cores. Imagine a large image needing to be processed. Each pixel of the image is assigned to a different core. Each core calculates the color and other characteristics of its assigned pixel, and then combines the results to form the final output.
This process, repeated for every pixel, effectively delivers the output in parallel.
+-----------------+
| Input Image Data |
+-----------------+
|
V
+-----------------+ +-----------------+
| GPU Processing |--->| Processed Image |
| Cores (Multiple) | +-----------------+
+-----------------+
|
V
+-----------------+
| Output Data |
+-----------------+
The above flowchart visually depicts the process of a GPU performing parallel operations.
The input data, in this case, an image, is distributed among multiple GPU cores. Each core independently processes its assigned portion of the data, and the results are combined to produce the final output. This parallel processing approach is fundamentally different from how a CPU handles tasks, leading to a considerable performance boost for GPU-optimized applications.
GPU Cores and Memory
GPUs excel at parallel processing, but their performance hinges critically on the efficient management of both processing cores and memory. This section delves into the specifics of GPU cores and the various memory types, illuminating the intricate memory hierarchy that fuels their power.
GPU Core Structure and Function
GPU cores, often called CUDA cores or stream processors, are highly specialized for parallel computations. These cores are designed to execute a large number of simple arithmetic and logic operations concurrently. Their structure often features a simplified instruction set and optimized data paths to achieve high throughput. A key characteristic of GPU cores is their massive parallelism.
Instead of focusing on complex, single-instruction tasks, GPU cores excel at executing many simple instructions simultaneously on different data sets. This allows them to tackle massive datasets and complex computations with remarkable speed.
Types of GPU Memory
GPUs utilize various memory types to facilitate efficient data access and processing. Understanding these different types and their roles within the memory hierarchy is essential to appreciating GPU performance.
- Global Memory: This is the primary storage location for data within the GPU. It’s a large, relatively slow memory accessible to all cores. Global memory is the central repository for data that needs to be shared across various parts of a computation. It serves as the primary interface between the GPU and the host system, where large datasets are loaded and results are stored.
- Shared Memory: This memory is smaller and significantly faster than global memory. It’s specifically designed for fast data sharing among nearby cores within a multi-core block or SM. Shared memory facilitates rapid data exchange within a group of cores working on a specific part of a computation, minimizing communication time and improving overall efficiency. Its locality of access allows for faster data retrieval.
- Local Memory: Each individual core in the GPU has its own local memory. This memory provides private storage for each core. This local memory is generally very small but highly accessible for temporary data storage. Local memory ensures that each core has its own workspace for intermediate calculations without needing to access shared memory, thus further optimizing performance.
This is crucial for situations requiring each core to operate independently.
Memory Hierarchy in a GPU
The memory hierarchy in a GPU mirrors the structure of the cores and their interactions. Data frequently moves from global memory to shared memory, and finally to local memory, as computations progress. This hierarchical structure is designed to optimize access time based on the frequency of access and the volume of data.
- Global Memory: This memory is the slowest in terms of access time but is the largest and provides the most storage space. Its role is to store large datasets, ensuring that data required for the computations is available. Transferring data to and from global memory is a crucial part of GPU computation and influences overall performance.
- Shared Memory: This memory is much faster than global memory and is crucial for inter-core communication. It allows for rapid data sharing within a block of cores, leading to a substantial speed-up in computation. The efficiency of shared memory is tied to the locality of operations, as data frequently used by a group of cores should reside in shared memory.
- Local Memory: This memory, closest to each core, is the fastest for individual core access. Its limited size is offset by its speed, making it suitable for temporary variables and intermediate results. The usage of local memory directly affects the efficiency of individual core computations.
Trade-offs Between Memory Types
The choice of memory type depends on the specific needs of the computation. Global memory is ideal for large datasets, but its access time can be a bottleneck. Shared memory is crucial for inter-core communication but has a limited capacity. Local memory provides the fastest access but has the smallest size.
Comparison of GPU Memory Types
| Memory Type | Speed | Capacity | Accessibility | Use Case |
|---|---|---|---|---|
| Global | Slowest | Largest | All cores | Storing large datasets |
| Shared | Faster than global | Smaller than global | Cores within a block | Inter-core communication |
| Local | Fastest | Smallest | Individual core | Temporary variables, intermediate results |
Sets and Programming Models: GPU Architecture Explained For Beginners
GPUs excel at parallel processing, but programmers need specific tools to harness this power. These tools, known as programming models, define how code interacts with the GPU’s architecture. Understanding these models is crucial for effectively leveraging a GPU’s capabilities.
Programming models dictate how developers structure their code to execute tasks on the GPU’s many cores concurrently. This involves mapping data structures and algorithms onto the GPU’s hardware. Different models offer varying levels of control and abstraction, affecting performance and complexity.
Specific Sets Used by GPUs
GPUs operate on data sets organized differently from CPUs. Instead of sequential access, GPUs often process data in blocks, allowing simultaneous operations on multiple elements. These blocks are often managed through indexing, enabling GPUs to access and manipulate data in parallel.
Programming Models for GPUs
Various programming models cater to different needs and expertise levels. They provide distinct approaches for writing code that utilizes the parallel processing power of GPUs. Some of the prominent ones include CUDA and OpenCL.
CUDA
CUDA, developed by NVIDIA, is a widely used parallel computing platform and programming model. It leverages NVIDIA’s GPU architecture directly, offering fine-grained control over hardware resources. This direct access often translates to high performance, but it can also make development more complex.
OpenCL
OpenCL is an open standard for heterogeneous computing. It allows code to run on various platforms, including CPUs, GPUs, and other accelerators. This portability is a significant advantage, but the abstraction layer can potentially lead to slightly lower performance compared to CUDA when targeting specific NVIDIA hardware.
Comparison of Programming Models
| Feature | CUDA | OpenCL |
|---|---|---|
| Platform | NVIDIA GPUs | Heterogeneous (CPUs, GPUs, etc.) |
| Portability | High (limited to NVIDIA GPUs) | High (across various platforms) |
| Performance | Generally high | Generally lower compared to CUDA for NVIDIA GPUs |
| Complexity | Higher | Lower |
Parallelizing a Simple Algorithm using CUDA
Consider a task of adding two vectors element-wise. Using CUDA, we can achieve parallelism by dividing the vector into blocks and assigning each block to a set of threads. Each thread can then compute the sum of corresponding elements in the input vectors. This approach distributes the work across multiple threads, significantly speeding up the process.
“`C++
// Example (simplified) CUDA code for vector addition
__global__ void vectorAdd(int
-a, int
-b, int
-c, int size)
int i = blockIdx.x
– blockDim.x + threadIdx.x;
if (i < size)
c[i] = a[i] + b[i];
```
This code snippet showcases a CUDA kernel. `__global__` indicates that the function runs on the GPU. The `blockIdx` and `threadIdx` variables are essential for thread management. The code efficiently distributes the work to individual threads, effectively performing the addition in parallel.
Data Flow and Pipelines
GPUs excel at parallel processing, but efficient data movement and organization are crucial for their performance. Understanding how data flows through the GPU architecture, particularly through pipelines, is essential for optimizing applications and leveraging the full potential of these powerful processors.
This section details the intricate pathways data takes within a GPU, focusing on the role of pipelines and potential bottlenecks.
Data Flow Through the GPU
Data, in various forms, travels through different stages within the GPU. This journey typically starts with data being loaded from the host system’s memory into the GPU’s memory. This transfer can be a significant factor in overall processing time. Once in the GPU memory, the data is then divided and distributed among numerous processing units, often in a streaming fashion.
Pipelines and Data Processing
The concept of pipelines is fundamental to GPU performance. A pipeline is a sequence of stages, each responsible for a specific task in the data processing sequence. Data moves sequentially through these stages, with each stage operating on the data as it passes through. This allows for overlapping operations, significantly improving throughput. For instance, in a graphics pipeline, vertices are transformed, textured, and rendered in a series of stages.
Data Transfer Between Components
Efficient data transfer between different components within the GPU is critical. This includes transfers between various memory levels (e.g., global memory, shared memory, registers) and between processing units. Data transfer mechanisms often employ optimized algorithms and hardware structures to minimize latency and maximize throughput. Sophisticated techniques like coalescing data access and caching mechanisms help reduce the overhead associated with these transfers.
Diagram of Data Flow in a GPU
Imagine a conveyor belt with several stations. The input to the conveyor is the host memory. Data is loaded onto the belt, and each station (or stage) performs a specific operation on the data. The first few stations might be responsible for data loading and transformation. Subsequent stations might perform more complex calculations, like matrix multiplications or other mathematical operations.
Finally, the processed data is collected at the output end and sent back to the host memory.
Bottlenecks and Solutions
Several factors can hinder efficient data flow within a GPU architecture. One key bottleneck is the rate at which data can be transferred between the host and the GPU. Solutions include optimizing data transfer mechanisms, using optimized data structures, and employing asynchronous data transfer techniques. Another bottleneck is inefficient use of memory resources. Strategies such as memory coalescing and careful memory management can significantly improve memory access performance.
Finally, the balance between the amount of data and the processing power available can affect performance. This is often addressed by carefully partitioning tasks and data across multiple processing units. In essence, understanding these bottlenecks is crucial for effectively utilizing GPU power and improving overall application performance.
Specific Architecture Examples

Source: techovedas.com
GPU architectures have evolved significantly, each generation bringing improvements in performance, efficiency, and programmability. Understanding these architectural differences is crucial for choosing the right GPU for a specific task and appreciating the progress in the field. Key features, trade-offs, and application suitability are discussed below.
Different GPU architectures employ varying approaches to achieve high levels of parallelism and data throughput. These variations often result in trade-offs between raw performance, power consumption, and programming complexity. The selection of a specific architecture depends on the desired balance of these factors.
NVIDIA’s Kepler Architecture, GPU architecture explained for beginners
Kepler, a significant advancement over previous architectures, introduced a novel approach to instruction dispatch and execution. The architecture focused on maximizing efficiency by combining different execution units for various operations. This approach included a mix of general-purpose cores and specialized cores tailored for specific tasks. The introduction of these specialized units significantly improved performance in certain applications.
AMD’s Graphics Core Next (GCN) Architecture
AMD’s GCN architecture, a departure from the traditional approach of previous generations, focused on a unified execution model. This means that all cores can execute any instruction, eliminating the need for specialized units. This unified approach simplifies programming but may not always achieve the same level of performance optimization as architectures with specialized cores.
Nvidia’s Volta Architecture
The Volta architecture marked a substantial leap forward in GPU design, particularly in terms of memory bandwidth and inter-core communication. It introduced innovative features, such as high-bandwidth memory interfaces and improved tensor cores for specialized operations. This design focus aimed to improve performance in AI and machine learning applications.
Comparison of Architectures
| Feature | Kepler | GCN | Volta |
|---|---|---|---|
| Execution Units | Mixed general-purpose and specialized cores | Unified execution model | General-purpose cores with enhanced tensor cores |
| Memory Bandwidth | Moderate | Moderate | High |
| Programming Model | CUDA | OpenCL, Mantle | CUDA |
| Applications | General-purpose computing, gaming | General-purpose computing, gaming, scientific simulations | AI, machine learning, high-performance computing |
Evolution of Architecture Features
The evolution of GPU architectures is marked by continuous improvements in core count, memory bandwidth, and specialized units. The shift from specialized units to a unified execution model, as seen in GCN, reflects a trend towards simplifying programming and achieving wider applicability. The focus on specialized tensor cores, as in Volta, signifies the increasing importance of AI-related workloads.
For example, the initial focus on graphics processing gradually broadened to encompass a broader range of computational tasks.
Applications and Examples
Kepler’s architecture proved successful in gaming and general-purpose computing tasks due to its balanced approach. GCN’s unified execution model enabled its use in various fields, from scientific simulations to general-purpose computing. Volta’s emphasis on tensor cores positions it as a strong choice for AI-related applications, showcasing the impact of architecture design on specialized workloads.
Applications and Use Cases
Source: slidesharecdn.com
GPUs, with their parallel processing capabilities and massive number of cores, have revolutionized various fields. Their suitability for handling complex computations and massive datasets has made them indispensable in many applications. This section delves into the diverse applications that leverage GPU architecture and highlights how their specific design features cater to these needs.
Gaming
GPUs excel at rendering graphics in real-time, a critical component in modern video games. Their ability to perform many calculations simultaneously allows for complex 3D models, realistic lighting effects, and smooth animations. Techniques like ray tracing and physically-based rendering, which involve extensive calculations, heavily rely on GPU acceleration. For instance, the intricate details of a realistic environment, like the shimmering reflections on water or the subtle variations in a forest canopy, are generated by GPUs performing complex calculations in parallel.
Scientific Simulations
Complex scientific simulations, such as modeling fluid dynamics, weather patterns, and molecular interactions, require immense computational power. GPUs, with their massive parallel processing capabilities, are exceptionally well-suited for these simulations. They can handle the large number of calculations needed to model these systems, providing insights into phenomena that would be intractable with traditional CPUs. For example, predicting climate change or understanding the behavior of a complex chemical reaction necessitates extensive simulations, where GPUs play a vital role.
Machine Learning
The rapid growth of machine learning relies heavily on GPUs. Machine learning algorithms, such as deep neural networks, involve numerous matrix multiplications and other computationally intensive operations. GPUs’ parallel processing architecture allows these algorithms to be executed significantly faster than on CPUs. Tasks like training large language models or image recognition systems are computationally demanding and efficiently handled by GPUs.
The vast amounts of data required for these models are also effectively processed by the massive memory capacity of GPUs.
Image and Video Processing
Tasks involving image and video processing, such as image editing, video encoding, and decoding, benefit greatly from GPU acceleration. These tasks involve numerous calculations on pixel data, making them ideal for GPUs. The rapid processing speeds of GPUs enable real-time video editing and processing, which is essential for applications like video streaming and content creation. For instance, video games often employ GPUs for real-time rendering, creating smooth visuals, which relies on efficient image processing techniques.
Other Applications
GPUs are increasingly used in a wide range of applications, including:
- Financial Modeling: Complex financial models often require substantial computational power, and GPUs can expedite calculations for risk assessment, portfolio optimization, and other tasks.
- Drug Discovery: Simulating molecular interactions and predicting drug efficacy are computationally intensive, benefiting from the parallel processing capabilities of GPUs.
- Medical Imaging: Analyzing medical images, such as CT scans and MRI data, requires substantial processing power. GPUs can expedite the analysis, aiding in diagnosis and treatment.
GPU Architecture Suitability Table
| Application | GPU Architecture Suitability | Specific Tasks/Operations |
|---|---|---|
| Gaming | Excellent; Real-time rendering, complex graphics, high frame rates | Rendering 3D models, simulating lighting effects, handling complex animations |
| Scientific Simulations | Excellent; Massive parallel computations, large datasets | Modeling fluid dynamics, weather patterns, molecular interactions |
| Machine Learning | Excellent; Matrix multiplications, deep neural networks | Training large language models, image recognition, data analysis |
| Image and Video Processing | Excellent; Pixel-based calculations, real-time processing | Image editing, video encoding/decoding, video streaming |
| Financial Modeling | Good; Complex calculations, large datasets | Risk assessment, portfolio optimization, market analysis |
Future Trends
GPU architecture is constantly evolving to meet the ever-increasing demands of modern applications. Advancements in chip fabrication, materials science, and software development are driving innovation in this field. These trends will significantly impact diverse industries, from gaming and scientific research to artificial intelligence and machine learning.
Potential Advancements in Chip Fabrication
Moore’s Law, while showing signs of slowing, still fuels the drive for smaller, faster, and more power-efficient transistors. This translates to GPUs with higher processing power, more cores, and lower energy consumption. This improvement is crucial for applications requiring intensive computation, like deep learning models, where energy efficiency is a key factor. For instance, the development of new materials, such as graphene or other 2D materials, could lead to transistors with even higher performance and lower power consumption.
FinFET transistors, already in use, continue to refine their architecture, improving performance and reducing energy consumption.
Enhanced Memory Architectures
Current GPU memory hierarchies face challenges in balancing bandwidth and latency. Future architectures will likely incorporate new memory technologies, such as high-bandwidth memory (HBM), and more sophisticated caching mechanisms. This will lead to faster data access and improved performance for complex algorithms, particularly in tasks that involve significant data movement between the GPU and host memory. Research into novel memory architectures, such as using 3D stacking for memory chips, aims to further increase memory capacity and bandwidth.
This is important for processing large datasets in applications such as image processing and video analysis.
Specialized Hardware for AI
AI workloads place specific demands on GPU architectures. The development of specialized hardware accelerators, integrated directly into the GPU, is a significant trend. These accelerators can optimize operations crucial for AI, such as matrix multiplication and tensor computations. The integration of these accelerators with existing GPU architectures will lead to significant performance gains in AI-related applications. Examples of this include dedicated tensor cores in modern GPUs, designed to improve deep learning training.
Software and Programming Models
Future GPUs will likely feature improved programming models, allowing developers to leverage their capabilities more effectively. Higher-level programming languages and frameworks are expected to become more sophisticated, abstracting away the complexities of low-level GPU programming. This will lead to easier development and deployment of applications requiring substantial parallel processing. Examples of this include CUDA, OpenCL, and newer programming languages specifically designed for GPU computation.
Research Directions
Current research focuses on improving the energy efficiency of GPUs, developing new memory architectures, and optimizing parallel algorithms. The study of novel interconnect technologies, such as advanced packaging techniques, aims to reduce latency and improve communication between components within the GPU. Other areas of investigation include specialized hardware units for specific tasks, such as machine learning, and new programming paradigms that better match the characteristics of GPUs.
Conclusion
In conclusion, this comprehensive guide to GPU architecture explained for beginners has provided a detailed overview of this crucial technology. We’ve examined the core concepts, the technical aspects, and the real-world applications. From parallel processing to specific programming models, we’ve covered a broad spectrum of information. The potential for future advancements in GPU architecture remains significant, promising even greater computational power and broader application possibilities.










Post Comment