Exploring The Role Of Gpus In Deep Learning And Ai
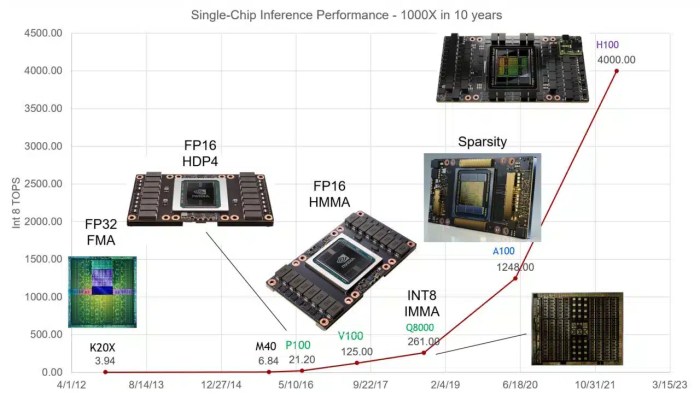
Exploring the Role of GPUs in Deep Learning and AI, this exploration delves into the crucial role of Graphics Processing Units (GPUs) in powering modern deep learning and artificial intelligence. From their humble beginnings in gaming to their current indispensable status in training complex AI models, GPUs have undergone a remarkable transformation. This in-depth look will examine the fundamental architectural differences between CPUs and GPUs, highlighting their respective strengths in parallel processing.
We will also investigate various GPU architectures, comparing their performance in deep learning tasks. This analysis will cover everything from the underlying algorithms to practical considerations, including data handling, optimized libraries, and the potential limitations of using GPUs in deep learning.
This comprehensive overview will cover the history of GPUs in deep learning, exploring how their parallel processing capabilities have revolutionized model training. We will discuss specific algorithms like backpropagation and matrix multiplication, and examine how GPU acceleration significantly impacts training time and model accuracy. A detailed examination of popular deep learning frameworks and their integration with GPU architectures will be included.
The discussion will also touch on the challenges and limitations of GPU usage in deep learning, and conclude with a glimpse into the future of GPU technology in AI development.
Introduction to GPUs and Deep Learning
Source: goonline.io
Graphics Processing Units (GPUs) have revolutionized deep learning, enabling the training of complex models that were previously computationally intractable. Their architecture, designed for parallel processing, provides a significant performance advantage over traditional Central Processing Units (CPUs) for the demanding tasks of deep learning. This shift has fundamentally altered the landscape of AI research and application.
Graphics Processing Units (GPUs) and their Architecture
GPUs are specialized electronic circuits designed to rapidly manipulate and alter numerous pieces of data simultaneously. Their architecture, characterized by a massive number of smaller, simpler processing cores, is fundamentally different from the single, complex core found in CPUs. This parallel processing capability makes them ideally suited for tasks involving massive datasets and complex calculations, such as those required in deep learning.
This distributed architecture allows GPUs to handle many operations simultaneously, accelerating computation. Modern GPUs utilize a hierarchical memory structure, including global memory and various caches, optimized for high-bandwidth data transfer and efficient access.
Evolution of GPUs from Gaming to Deep Learning
Initially designed for accelerating graphics rendering in video games, GPUs gradually evolved to support other computationally intensive tasks. The parallel processing power, coupled with advancements in hardware and software, made them increasingly suitable for general-purpose computation. This trend culminated in their adoption as a crucial tool for deep learning, where their ability to handle massive amounts of data and perform complex calculations simultaneously proved invaluable.
The rise of deep learning applications further drove the evolution of GPU architecture, resulting in increasingly specialized and optimized designs.
Fundamental Differences between CPUs and GPUs
CPUs excel at handling a wide range of tasks sequentially, while GPUs are optimized for handling a large number of tasks concurrently. This fundamental difference in approach translates into significant performance disparities when dealing with the massive computations inherent in deep learning. CPUs, with their single core, struggle to keep pace with the data deluge, whereas GPUs, with their multitude of cores, can efficiently tackle such challenges.
This parallel processing advantage is critical for the complex calculations needed in training deep learning models.
CPU vs. GPU Characteristics for Deep Learning Tasks
| Characteristic | CPU | GPU | Deep Learning Task Impact |
|---|---|---|---|
| Processing Cores | Single, complex core | Thousands of smaller, simpler cores | GPUs excel at parallel tasks, CPUs struggle with massive data processing. |
| Memory Bandwidth | Relatively low | High | GPUs handle data transfer efficiently, critical for training large models. |
| Parallel Processing | Limited | Exceptional | GPUs’ parallel processing capabilities are key to training deep learning models quickly. |
| Instruction Set | General-purpose | Specialized for vector and matrix operations | GPUs’ tailored instruction set optimizes for deep learning algorithms. |
GPU Architectures for Deep Learning
GPUs have revolutionized deep learning, enabling the training of complex models that were previously computationally infeasible. Different GPU architectures, each with its unique strengths, play a crucial role in this acceleration. Understanding these architectures and their key components is essential for leveraging the full potential of GPUs in deep learning tasks.Various GPU architectures are tailored for deep learning workloads, each offering specific advantages in terms of performance and efficiency.
NVIDIA CUDA and AMD ROCm are two prominent examples, and their distinct features allow for diverse choices depending on specific project requirements.
NVIDIA CUDA Architecture
The NVIDIA CUDA architecture is a widely adopted platform for deep learning, renowned for its performance and extensive ecosystem. CUDA’s parallel computing capabilities are optimized for tasks like matrix multiplication and tensor operations, fundamental to deep learning algorithms. It leverages specialized hardware units designed for efficient numerical computation, enabling high throughput. The CUDA programming model simplifies the process of parallelizing algorithms, making it accessible to developers.
AMD ROCm Architecture
AMD ROCm is an open-source platform for heterogeneous computing, including GPUs. ROCm aims to provide an alternative to NVIDIA CUDA, focusing on scalability and flexibility. Key components in ROCm include a compiler infrastructure (ROCm Compiler) and runtime libraries, designed to manage the interactions between the CPU and GPU. This approach allows for efficient data transfer and task management between the two.
ROCm offers a potential alternative for users seeking open-source solutions and control over the hardware utilization process.
Key Components Relevant to Deep Learning
Several key components of these architectures are essential for deep learning performance. These include the streaming multiprocessors (SMs), which execute the kernels; the global memory, used for data storage; and the shared memory, enabling fast communication between threads. The memory hierarchy, encompassing global, shared, and register memory, plays a crucial role in minimizing data transfer bottlenecks. Efficient utilization of these components directly impacts the speed and efficiency of deep learning training.
Performance Comparison
Performance comparisons of different GPU architectures in deep learning are often context-dependent. Factors like the specific deep learning model, dataset size, and hardware configuration significantly influence the outcomes. Generally, NVIDIA GPUs have historically held a dominant position in deep learning, though AMD has been steadily improving its performance and offering competitive solutions. Benchmarking studies and real-world applications provide valuable insights into the performance of different architectures.
GPU Architectures Comparison
| Architecture | Key Feature | Strengths | Weaknesses |
|---|---|---|---|
| NVIDIA CUDA | Proprietary, extensive ecosystem, high performance | Mature ecosystem, extensive libraries, high performance in many benchmarks | Proprietary, limited control over low-level details |
| AMD ROCm | Open-source, flexible, growing ecosystem | Potential for customization, competitive performance in certain workloads, increasing community support | Ecosystem still developing, fewer readily available optimized libraries compared to CUDA |
Deep Learning Algorithms and GPU Acceleration: Exploring The Role Of GPUs In Deep Learning And AI

Source: cnvrg.io
Deep learning algorithms, at their core, rely on intricate calculations involving vast datasets and complex mathematical operations. These computations are often computationally intensive, demanding substantial processing power to achieve timely results. GPU acceleration plays a pivotal role in mitigating these computational bottlenecks, enabling researchers and practitioners to train sophisticated models and achieve breakthroughs in various AI applications.Deep learning algorithms, particularly those with multiple layers, necessitate the repeated execution of numerous calculations.
GPUs excel at handling these parallel computations, dramatically reducing the time required for model training. This acceleration is directly attributable to the architecture of GPUs, which are designed with a massive number of smaller, specialized processors that can work simultaneously.
Backpropagation and GPU Parallelism
Backpropagation, a crucial algorithm in training deep neural networks, involves calculating gradients to adjust the weights and biases of the network. The iterative nature of this process lends itself perfectly to GPU acceleration. The calculation of gradients for each neuron in the network can be performed independently by different GPU cores, thus dramatically reducing the overall training time.
This parallelization is a key factor enabling researchers to train deep neural networks with millions of parameters in reasonable timeframes.
Matrix Multiplication and GPU Efficiency
Deep learning algorithms heavily rely on matrix multiplication. The computational complexity of these operations scales rapidly with the size of the matrices involved. GPUs are highly optimized for matrix multiplication, leveraging their parallel processing capabilities to execute these operations with unparalleled efficiency. This optimized execution contributes to a substantial reduction in training time for deep learning models.
Impact on Training Time and Model Accuracy
GPU acceleration significantly impacts training time. Training a deep learning model on a CPU can take days or even weeks, whereas a GPU can drastically reduce this time to hours or even minutes. This accelerated training time translates into faster development cycles, allowing researchers to iterate and refine models more rapidly. Importantly, this acceleration does not compromise model accuracy.
In fact, faster training enables the exploration of larger datasets and more complex architectures, ultimately leading to improved model performance.
Examples of GPU Utilization in Deep Learning Models
- Convolutional Neural Networks (CNNs): CNNs, extensively used in image recognition and processing, leverage the parallel processing power of GPUs to efficiently perform convolutional operations on large image datasets. The parallel execution of these operations on multiple image regions significantly reduces training time, allowing for the training of complex CNN models capable of identifying intricate patterns and objects in images.
- Recurrent Neural Networks (RNNs): RNNs, employed in natural language processing and time series analysis, benefit from GPU acceleration in handling sequential data. The parallel execution of operations on different time steps within the sequence, facilitated by GPU parallelism, enables efficient training of RNN models for tasks like language translation and speech recognition.
Different Deep Learning Model Architectures
Deep learning model architectures, such as CNNs, RNNs, and Transformers, all benefit from GPU acceleration. Each architecture utilizes different computational operations, but the inherent parallelism of GPUs enables significant performance gains across various deep learning tasks.
Data Handling and Transfer in Deep Learning with GPUs
Efficient data transfer between the CPU and GPU is critical for the performance of deep learning tasks. The GPU, while powerful for parallel computations, is often separated from the main memory where the training data resides. This necessitates a streamlined process for moving data, ensuring minimal delays and maximizing GPU utilization. Optimized techniques are paramount for accelerating model training and achieving satisfactory results in a timely manner.
Data Transfer Mechanisms
The transfer of data between the CPU and GPU is facilitated by various mechanisms, each with its own characteristics and performance implications. These methods are designed to optimize data movement and minimize latency. One common approach involves copying data directly from the CPU’s main memory to the GPU’s dedicated memory space. Other techniques leverage specialized libraries or hardware-accelerated transfers.
Importance of Optimized Data Transfer
Optimized data transfer techniques are crucial for GPU performance in deep learning. Inefficient data transfer can significantly impede training speed. By minimizing data transfer times, GPU utilization increases, enabling faster model training, particularly with large datasets. This translates to quicker insights and reduced overall project timelines. For example, a model trained on a dataset with a slow data transfer process might take several days to complete, while a model using optimized techniques can finish in a fraction of that time.
Bottlenecks in Data Transfer
Several factors can act as bottlenecks in data transfer between CPU and GPU. One significant bottleneck is the limited bandwidth between the CPU and GPU memory. Another bottleneck stems from the data transfer process itself, which can introduce delays if not optimized. Inefficient memory management on either the CPU or GPU side can also exacerbate these delays.
Furthermore, the size of the data being transferred can significantly impact the transfer time. Larger datasets require more time for transfer, potentially leading to substantial delays in training.
Strategies to Mitigate Bottlenecks
Various strategies can be employed to mitigate these bottlenecks. Techniques like using optimized data structures and algorithms can significantly reduce the amount of data that needs to be transferred. Employing asynchronous data transfer methods, where the GPU can begin processing data while the CPU continues loading new data, can further enhance efficiency. Moreover, utilizing libraries specifically designed for GPU data transfer, such as those found in CUDA or cuBLAS, can yield performance improvements by leveraging specialized hardware features.
Memory Management in Deep Learning Training
Effective memory management is vital for deep learning training on GPUs. Training deep learning models often requires handling massive datasets and complex computations. Proper memory management ensures efficient allocation and deallocation of GPU memory, preventing memory leaks and maximizing the utilization of the available GPU resources. Memory leaks, where allocated memory is not freed, can lead to decreased performance or even system crashes.
Therefore, careful management of GPU memory is crucial to maintain optimal training performance. For example, a model that fails to manage memory effectively may run out of space during training, causing the process to halt prematurely.
Data Structures and Deep Learning, Exploring the Role of GPUs in Deep Learning and AI
Choosing appropriate data structures plays a crucial role in optimizing data transfer. Utilizing optimized data structures, such as those designed for parallel processing, can enhance data transfer speed. For instance, using optimized matrix operations can improve efficiency when dealing with large matrices in deep learning models.
GPU-Specific Deep Learning Libraries and Frameworks
GPU-accelerated deep learning libraries have become indispensable for researchers and practitioners in the field. These specialized libraries leverage the parallel processing capabilities of GPUs to significantly accelerate training and inference processes, enabling the development of complex models and pushing the boundaries of AI.These libraries abstract away much of the low-level GPU programming, allowing developers to focus on the model architecture and data without needing to worry about the intricacies of GPU memory management or parallel computations.
This greatly simplifies the development process and makes deep learning accessible to a broader audience.
Prominent GPU-Accelerated Deep Learning Libraries
Several prominent libraries stand out for their GPU acceleration capabilities. TensorFlow, PyTorch, and CUDA are among the most popular choices. Each offers unique features and strengths, catering to different needs and preferences.
- TensorFlow, developed by Google, is a versatile and widely adopted framework known for its extensive ecosystem and production-level capabilities. It’s particularly well-suited for large-scale deployments and complex models, offering robust features for distributed training and deployment.
- PyTorch, developed by Facebook, is another leading framework gaining immense popularity due to its dynamic computation graph and user-friendly interface. Its flexibility makes it a preferred choice for research and prototyping, allowing for rapid experimentation and model customization.
- CUDA, developed by NVIDIA, provides a comprehensive suite of tools and libraries for GPU programming. It offers low-level control over GPU resources, allowing for fine-tuning performance in specific applications. However, it typically requires more expertise compared to higher-level frameworks like TensorFlow and PyTorch.
Benefits and Limitations of Using GPU Libraries
These libraries offer significant advantages for GPU-based deep learning.
- Benefits: Reduced training time, enhanced model complexity, and improved performance are key benefits. By offloading computations to GPUs, these libraries enable faster training of larger, more intricate neural networks, leading to improved model accuracy and efficiency. This translates into quicker insights and faster development cycles for AI applications.
- Limitations: A significant limitation is the need for appropriate hardware. Powerful GPUs are required to fully leverage the potential of these libraries, and the cost of such hardware can be a barrier for some users. Furthermore, while higher-level libraries simplify the process, specialized knowledge might be needed to optimize performance for very specific tasks or complex models.
GPU Optimization Functionalities
These libraries offer functionalities to optimize GPU utilization for deep learning tasks.
- Automatic Differentiation: Libraries like TensorFlow and PyTorch use automatic differentiation to calculate gradients efficiently, a crucial aspect of backpropagation in neural networks. This significantly speeds up the training process.
- Memory Management: Sophisticated memory management techniques are implemented to efficiently allocate and manage GPU memory, minimizing memory bottlenecks and maximizing GPU utilization. This is crucial to avoid issues like out-of-memory errors and to ensure smooth execution.
- Parallel Computing: These libraries utilize parallel processing to execute multiple operations concurrently on the GPU, leading to significant performance gains in tasks like matrix multiplication and convolution. This is the cornerstone of GPU acceleration in deep learning.
Performance Comparison of Deep Learning Frameworks
The performance of deep learning frameworks varies depending on the specific GPU architecture. A direct comparison is complex, but a table illustrates the potential differences.
| Framework | Nvidia GeForce RTX 4090 | Nvidia GeForce RTX 3090 | AMD Radeon RX 7900 XTX | Intel Arc A770 |
|---|---|---|---|---|
| TensorFlow | Excellent | Excellent | Good | Moderate |
| PyTorch | Excellent | Excellent | Good | Moderate |
| CUDA | Excellent (with custom code) | Excellent (with custom code) | Good (with custom code) | Limited (requires significant optimization) |
Note: “Excellent” signifies superior performance, “Good” indicates solid performance, and “Moderate” denotes average performance. Actual results can vary based on the specific model architecture, dataset, and implementation details.
Challenges and Limitations of Using GPUs in Deep Learning
Source: co.kr
Deep learning models, particularly complex ones, often require significant computational resources. GPUs, while offering substantial acceleration, are not without their limitations. Understanding these challenges is crucial for effectively utilizing GPUs and achieving optimal performance.
Memory Capacity Limitations
GPU memory, while vast compared to CPUs, is still finite. Large datasets and intricate models can easily exceed available VRAM. This limitation frequently necessitates techniques like data partitioning and gradient accumulation. These strategies divide the workload and data, processing smaller batches in multiple steps.
Computational Power Limitations
While GPUs excel at parallel computations, certain deep learning tasks, especially those involving intricate calculations or specialized algorithms, might still find CPUs more efficient. The choice between GPU and CPU often depends on the specific model and its computational demands. For instance, a computationally intensive neural network might benefit from a GPU, while simpler tasks might be better served by a CPU.
Data Transfer Bottlenecks
Transferring data between the GPU and the host memory (system RAM) can create performance bottlenecks. Large datasets necessitate considerable data movement, leading to delays and reduced overall throughput. Optimization techniques, like using optimized data transfer libraries and careful batching, can significantly mitigate these bottlenecks.
Practical Strategies to Overcome Limitations
Several strategies can help mitigate the limitations associated with GPU usage in deep learning. One approach is to employ techniques for efficient data handling. This includes minimizing data transfer operations, employing optimized libraries, and strategically partitioning data. Another critical strategy involves careful model design. Using smaller, more manageable models or models optimized for specific hardware can dramatically improve efficiency.
Finally, selecting the appropriate hardware and software configuration is critical. Using GPUs with sufficient VRAM, choosing optimized libraries, and implementing appropriate data transfer methods are crucial steps to overcome limitations.
Future Trends and Developments in GPU Deep Learning
The relentless pursuit of higher performance and efficiency in deep learning continues to drive innovation in GPU design and utilization. Emerging trends in both hardware and software are poised to significantly impact the field, offering substantial improvements in model training speed and accuracy. This evolution is critical for addressing the increasing demands of complex AI applications and unlocking further breakthroughs in artificial intelligence research.
Advanced GPU Architectures
Modern GPUs are designed with deep learning in mind, incorporating specialized hardware units and memory structures to optimize computations. Future designs will likely emphasize further advancements in these areas. These include:
- Increased Tensor Core Capacity: Tensor cores, specialized for matrix multiplication operations crucial in deep learning, will likely see substantial increases in their computational capacity. This will translate to even faster processing of large datasets and more complex models. For instance, a 10x increase in tensor core count compared to current architectures would translate to a significant performance boost for training large language models.
- Enhanced Memory Bandwidth: High bandwidth memory interfaces are essential for transferring massive datasets between memory and processing units. Future designs will prioritize faster and more efficient memory interfaces, minimizing bottlenecks and enabling faster model training.
- Heterogeneous Computing: The integration of CPUs, GPUs, and specialized accelerators (e.g., FPGAs) into a single system will allow for more efficient task distribution, maximizing the potential of each component. This heterogeneous approach will allow for more sophisticated and intricate deep learning workflows.
Software Advancements and Optimizations
Parallel to hardware developments, software optimizations are equally critical for leveraging the power of GPUs. These include:
- Automated Model Compilation: Tools that automatically translate deep learning models into highly optimized GPU code will significantly reduce the time and expertise required for model deployment. This will enable broader access to GPU-accelerated deep learning capabilities.
- Improved Training Algorithms: New algorithms for training deep learning models will be designed to leverage the specific capabilities of GPUs even more effectively. This will include optimized gradient descent methods tailored for different types of GPU architectures.
- Advanced Data Handling Techniques: Techniques for efficiently loading, preprocessing, and transferring data to and from GPUs will be further refined. This will minimize data transfer bottlenecks and further enhance training speed. Efficient use of memory management will be critical in this regard.
Future Potential and Impact
The combination of these advanced GPU architectures and software optimizations will dramatically accelerate AI research and development.
- Faster Model Training: The expected speed improvements will allow researchers to train more complex and larger models, leading to more accurate and powerful AI systems. Examples include training larger language models with greater vocabulary and understanding, leading to more human-like conversational AI systems.
- Enhanced AI Capabilities: Increased processing power will allow for the development of more sophisticated AI applications in diverse domains like autonomous vehicles, medical diagnosis, and personalized medicine. This will lead to a more efficient and accurate diagnosis process in medical settings.
- Accessibility and Democratization: The optimized software and hardware will make deep learning more accessible to a wider range of researchers and developers. This is crucial in expanding the talent pool and promoting further innovation in the field.
Performance Implications
These advancements will translate to significant improvements in the performance of deep learning models. Training times for complex models will decrease substantially, allowing for faster iterations and more efficient research cycles. Model accuracy may also improve, as the ability to train larger and more sophisticated models will lead to better generalization and reduced overfitting.
Ultimate Conclusion
In conclusion, GPUs have become integral to the advancement of deep learning and AI. Their parallel processing capabilities drastically reduce training times, allowing for the development of increasingly complex models. While challenges like memory capacity and data transfer remain, ongoing innovations in GPU architecture and deep learning frameworks continue to address these limitations. The future looks bright for the continued collaboration between GPUs and AI, promising even more sophisticated and powerful AI systems in the years to come.










Post Comment